
孫宇聰:評判云服務靠譜程度
云服務真的靠譜嗎?相信對這個問題每個人心里都有不同的答案。我今天想講的是如何客觀的去回答這個問題,其中結合了Coding的一些實踐和思考。...
云服務真的靠譜嗎?
相信對這個問題每個人心里都有不同的答案。我今天想講的是如何客觀的去回答這個問題, 其中結合了 Coding 的一些實踐和思考。

廣義范圍的“靠譜” 有幾個比較重要的點。
第一個點就是 Availability (可用性),24x7隨時可用。一個靠譜的云服務一定是可用性非常高的。
第二點是 Access Control,可控性一定要好,非云服務你可以上個鎖,云服務如何能做到可控性很好,很難。
第三點是 災難恢復,是軟件就會有問題。怎么樣積極的面對這個問題,這是任何一個云廠商都要誠實面對的問題。
可用性
首先第一點我們看來講一下可用性,可用性只有一個評判標準,就是 SLA,Service Level Agreement,更多的時候是 SLO, 只是 Objective。 一個東西是不是高可用,那么就問他幾個九,敢不敢拿出來說一下。
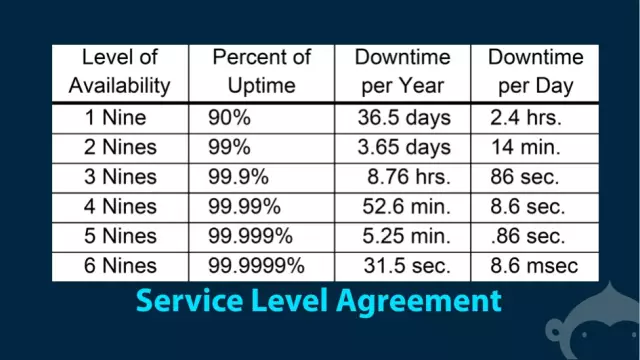
實實在在的看著這個圖說話,3個9基本上是國內云服務的基礎線。也就是說**云服務至少要做到3個9才稱為基本上可用**,是合格性產品。如果是做不到這個,你的東西就只是玩具,快回去好好把技術內功修煉修煉再出來刷臉。從3個9邁向4個9,也就是99.99%的可用性,每年只有52.6分鐘的時間是不可用的。
以前的谷歌搜索可用度大概是全球5個9到6個9之間,每一個小節點都是5個9不到6個9之間。想想吧,這其實是很可怕的一個概念。**因為這里包含了可能發生的一切事故**,不管什么不可抗力,都是扯淡。地震、洪水、臺風、大樓震塌了,也是5分鐘內恢復服務。
相比之下,大部分國內的IDC機房都是按照99%設計的,一年至少3天是不可用,這3天給你花在元旦一天,春節一天,國慶一天,省點時間給你機動(笑)。這里不可用就是不可用,求爺爺告奶奶也照樣不能用。
所以說 SLO 直接反映一個云服務的靠譜程度:
從99%到3個9,是基本可以靠堆人和運氣解決的;
從3個9到4個9,考驗的是運維自動化的能力,災備的能力;
從4個9往上基本考驗的是服務基礎架構、業務設計的能力。
我們也在3個9到4個9之間努力, 這個還是很有難度的。如果一個云服務廠商在注釋里加了句“不可抗力排除在外”,這是非常不合適的。
那么如何提升可用性:
Design For Redundancy, 第一是一定要做到所謂的**“無狀態微服務”**,去掉單點故障。 首先是“微服務”, 一個服務分解的越簡單,出錯的面就越小,失敗模式就越固定。然后是“無狀態”,這樣才可以做到無限擴展。 這個很難的, 很多時候最后拆來拆去都發現有一個數據庫在最后,這個數據庫就做不到無狀態,永遠只能有一個數據庫,一個數據庫實例在那擺著,可用性永遠上不去。
有了無狀態的微服務這種架構,還要做到 N+2。很多時候很多廠商連N都不知道(因為從沒有做過壓力測試,性能分析),何談N+2?
Design For Gradual Deployment, 第二就是要**支持灰度發布**。一個服務要前進,任何軟件組件都要改,都會改。更新操作會直接提高你系統出問題的可能性。想要提高可用性,**必須將發布的代價降低**。只有能夠做到說我上線一個新功能,只給某幾個用戶用,其他的用戶不受這個影響。這樣才能提高你整個系統作為一個整體的可用性,
Design for Clustering: 第三點是要**區分 Cluster management 和 App Managment 的概念, 把資源的調配和服務調配分開。**

Design for Automation ,最后一點是**自動化**。一個靠譜的云服務,從設計之初就把人的因素排除在運行之外。整個系統應該是全自動化運行的,不需要你人來干預。云服務初期買了二三臺個服務器,服務器放在那,有人天天盯著它才正常運行,這還有可能,上了規模之后顯然是不可能的。這是最關鍵的一點。任何一個云服務到現在內部都是非常復雜的,他就像這個漫畫里邊這樣,每一個人操作它的時候,面前有無數的按鈕,無數的可能性。除了問題之后,如果讓一個人馬上搞清楚弄明白立刻解決,這是不可能的,只能自動化。
而且其實更多的時候都是人的操作帶來的問題,更新一個軟件,更新一個服務器都不可避免的有人要參與。如果不做自動化,早晚會出問題。

任何的靠譜的云服務廠商至少要做到以下幾點:
第一個SLA一定要達到4個9,你達不到這個4個9基本上相當于你這個服務就是一個玩具,根本沒有辦法依賴你。
第二個是一個數量級,甚至兩個數量級以上的預研。
第三就是 Automation 自動化。這就是實踐中的一個經驗。