
基于真實用戶行為的云端壓力測試和業務容量規劃實例
云智慧產品總監陸興海高速增長的互聯網業務要求產品開發、迭代和交付周期越來越短,而IT基礎設施的廣泛云化和第三方API接口的大量使用,使傳統的基于內部...
云智慧產品總監 陸興海
高速增長的互聯網業務要求產品開發、迭代和交付周期越來越短,而IT基礎設施的廣泛云化和第三方API接口的大量使用,使傳統的基于內部環境搭建的壓力測試方法和測試工具越來越難以滿足應用功能可用和容量規劃預估的需求。
企業該如何為頻繁的市場活動和產品快速迭代進行有效而準確的壓力測試呢?希望通過云端壓力測試專家,云智慧壓測寶產品總監陸興海分享的兩個客戶案例,為企業的云端壓力測試和業務容量規劃帶來一些有價值的參考。
壓測寶云壓測客戶案例1:壓測寶如何做業務容量的測試與規劃?
云智慧有個做旅游和攝影服務平臺的客戶要舉辦一次活動,為本次活動制作了專門的活動頁面,在活動頁面用戶可以報名。那么在短時間內系統到底能撐得住多大的用戶并發?

這是活動運營和技術部門必須提前考慮的問題,因為在去年舉辦類似活動時就出現了用戶大量涌入導致服務不可用的狀況,所以首先要幫助用戶整理容量測試和規劃的工作思路。
具體該如何實施壓測呢,這里劃分了幾個環節:
[1]場景確定與壓測腳本準備
用戶在注冊時需要提交用戶的姓名、手機號和手機驗證碼,之后提交申請即可,所以實際上用戶申請注冊只調用了一個API接口來完成,這是一個比較簡單的場景。
1、因為涉及到手機驗證場景,在不提供對應API的情況下,建議用戶使用萬能的驗證碼或者暫時取消驗證碼;
2、是否允許多個手機號同時注冊,如果允許我們可用使用固定參數傳遞,如果不允許,我們可準備對應手機號的測試數據來應對;
3、短時間內發起大量并發,用戶本身是否有安全擋板,如果有,需要把施壓節點的IP加入白名單;
[2]施壓模式
既然是容量探測,所以整體的施壓過程是一個梯度漸進的過程,一般不會上來就是一條直線。這是一直和用戶強調的問題,壓測的目的絕對不是把系統壓垮,壓測的目的是通過不斷增加的并發來客觀評估系統在不同的壓力條件下的性能狀況;基于此我們定制了施壓的梯度壓力模式,如圖所示:
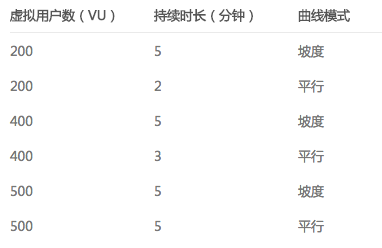
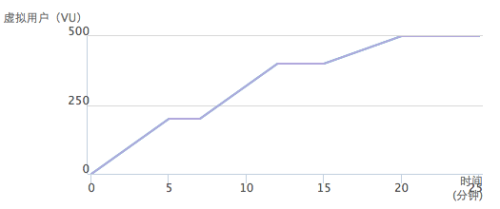
[3]壓測點分布
傳統壓力測試工具主要在內網產生壓力,壓力的規模受限于物理機器及License數量,造成準備周期長及成本高等問題。而云壓測提供可靠的分布式壓測服務器(壓測點),充分利用云端的計算資源,從而突破了這個限制。
目前云智慧的壓測點來自云服務的云主機(AWS、Ucloud和阿里云等)以及云智慧部署在全國各大IDC核心機房的服務器,目前主要提供的區域如下圖所示:

[4]壓測時間設定
根據系統訪問情況,一般會建議用戶在凌晨進行壓測,此時能夠保證對用戶的影響最小,也能保證正常用戶訪問對壓測結果的干擾最小。但這個壓測時間設定不是絕對的,需要與具體用戶的業務場景結合判斷。
[5]壓測數據分析
在基本的參數確定之后,就可用根據預定的時間來執行壓測任務了,云壓測能夠進行秒級的數據采集和實時統計分析,能夠隨時調整壓力。隨著壓力的逐步上升,能夠動態呈現系統的性能數據。在逐步加壓的過程中,如果性能急劇下降或大量出錯,就沒有必要繼續執行壓測任務,此時可以終止任務,也可以下調壓力,確保對整個壓測過程的把控。
針對這個用戶,按照上述步驟實施壓力測試之后,通過相關測試結果的數據分析和評估,得到了壓測結論如下:
被壓測的注冊接口在360并發用戶以下時表現相對良好,在并發用戶達到360至500時性能欠佳,說的更直接一點就是:該系統能夠支撐360的并發,具體論證如下:
1、并發達到360之后失敗明顯增多并且持續到任務結束;
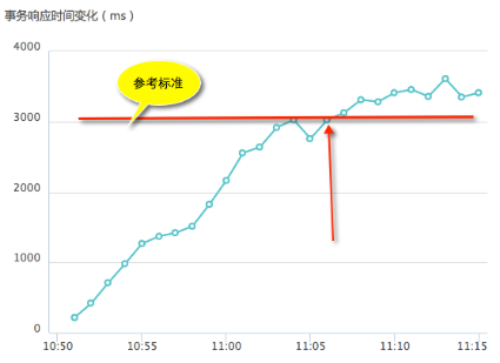
2、并發達到420之后,響應時間超出3000ms標準值且持續到最后;
3、每秒鐘事務數(TPS)穩定在130左右,表現比較良好;
本次壓測的概要數據如下圖所示:
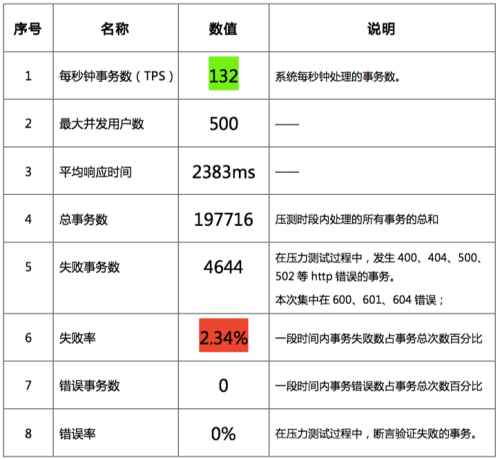
壓力測試綜合報表如下圖所示,當并發用戶數達到360時,系統開始出現了大面積失敗(280時出現了1次錯誤),并且失敗問題持續到壓測結束都沒有改善,不過整個測試過程中并沒有出現斷言不匹配的情況,即正確性保持良好。

事務響應時間趨勢:隨著應用訪問用戶量增加,在并發用戶達到420的時候,系統事務處理的時間也顯著上升(大于參考標準3000ms),且響應時間在以后一直沒有下降。
事務處理性能趨勢:當壓力穩步上升后,應用事務處理能力保持平穩,基本維持在每秒鐘處理130個左右事務,該數值基本能保障并發用戶注冊的需求。
壓測寶云壓測客戶案例2:基于壓測的后端性能問題分析與定位
下面介紹另外一個用戶的真實需求場景,這里著重分析用戶在壓測時遇到的性能問題,主要從失敗和響應時間緩慢兩個角度,首先是失敗情況,如下圖所示,失敗的類型及其占比。
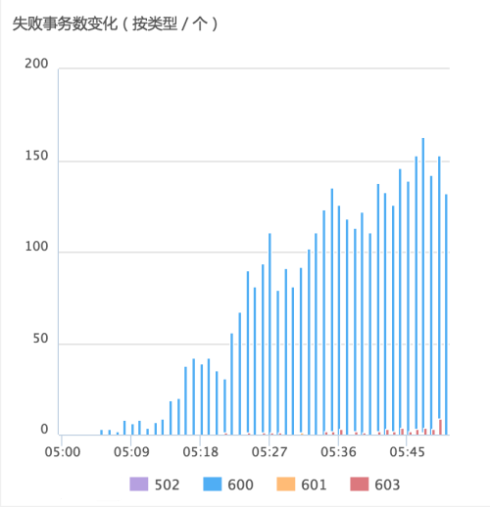
在整個測試過程系統從5:05分開始出現逐漸增加的不同類型服務器處理錯誤,導致事務處理失敗,具體錯誤信息如下:
502:錯誤網關(從5:43~5:46共出現112次502錯誤);
600:connection連接異常,從5:05~5:50共出現264次600錯誤);
601:Socket異常(5:31和5:47出現2次601錯誤);
603:拒接服務錯誤(從5:21至5:49共出現48次603錯誤);
其實是響應時間分析,如下圖所示某個事務及其對應的請求情況。
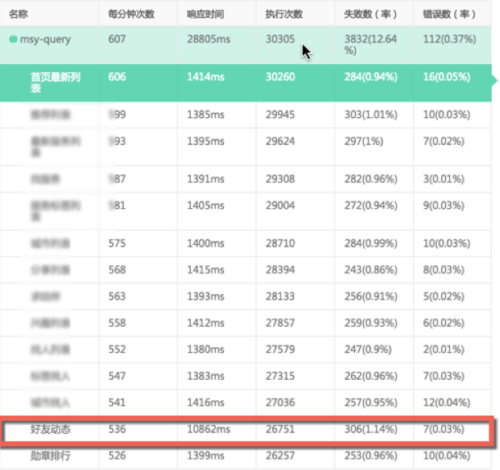
從上圖可以看出“好友動態”的平均事務請求響應時間為10,862ms,是其他應用請求的平均響應時間的7倍(其他請求平均響應時間為1,400ms)。
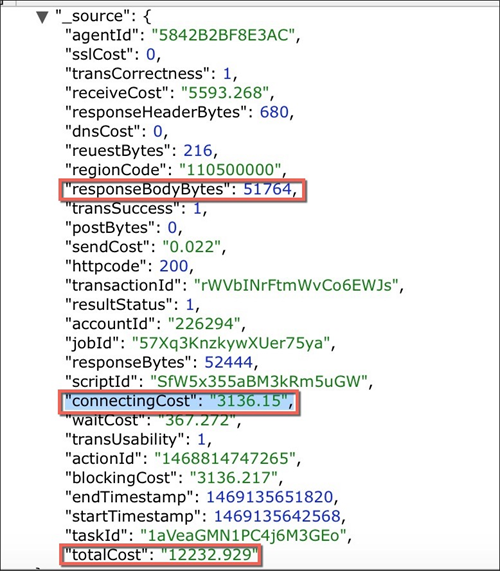
上圖為從壓測寶系統獲取的一次好友動態事務請求響應日志,可以看出響應時間為12232ms,其中連接時間為3136ms,請求返回的內容非常大(51764Bytes)。和其他應用相比好友動態應用耗時非常長,用戶體驗很差。
在本次壓測的全程,基于云智慧的應用性能管理產品透視寶來進一步分析后端性能情況,通過后端應用請求分析可以查看一段時間內Web應用處理事務請求的響應時間、請求數及詳細的請求信息及變化趨勢。在并發用戶超過200時響應時間明顯變慢,但整體系統響應時間表現正常(處理時間小于500ms占比74.13%);
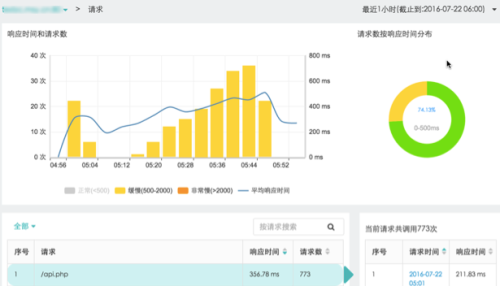
接著我們利用透視寶的代碼級堆棧定位分析功能來進一步分析數據庫SQL情況,如下圖所示。
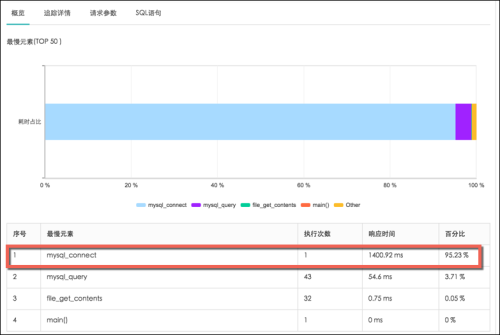
通過后端關鍵事務快照可以看出單次請求處理的數據庫連接耗時1400.92ms,占比95.23%(總響應時間1471.02ms),是主要的數據庫耗時來源;


可以看出數據庫查詢操作耗時占比3.71%,是數據庫第二耗時來源;而且多個數據庫查詢SQL語句大部分查詢條件相同,在高并發量用戶查詢時有較大的性能優化空間。
基于以上的分析,建議用戶從如下方面進行優化:
1)如果應用處理入口有前置負載均衡服務器,建議對負載均衡服務器相關參數進行優化,提升用戶請求入口處理能力;同時建議對負載均衡服務器進行性能監控,及時發現系統瓶頸;
2)事務請求處理過程中數據庫連接耗時較長,建議采用數據庫連接池組件進行性能優化;
3)建議在系統架構中增加數據庫緩存,同時對類似的SQL操作進行處理優化,以減少后端數據庫的連接次數,提高數據庫查詢效率和性能;
基于請求的深入分析,在壓測寶中提供問題請求的詳細快照,包括請求的響應時間分解、請求頭和返回結果,如下圖所示。
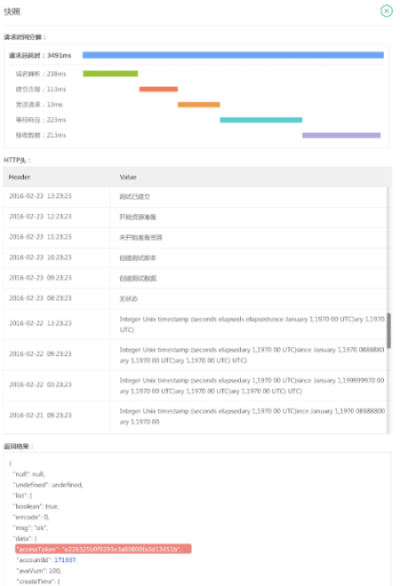
另外如上面所示,在壓測寶的單次請求追蹤部分集成了性能管理產品透視寶,能夠通過單次請求直接查看后端的代碼問題,如下圖所示:
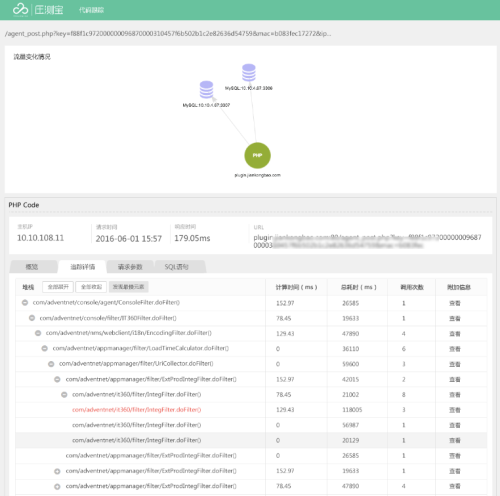
通過對失敗、緩慢與錯誤的事務與請求進行細化分析,包括對錯誤類型分析、請求快照查看以及后端深入定位。
以上是兩個真實應用場景的云端壓力測試分析案例,通過性能壓力測試(壓測寶)我們可以清楚的知曉業務容量規劃,并發現系統中影響業務的性能問題(請求緩慢、失敗)。通過與應用性能管理(透視寶)集成來定位和診斷根源問題,深入分析后端的性能瓶頸來提升業務質量,從而實現應用的快速優化和上線。